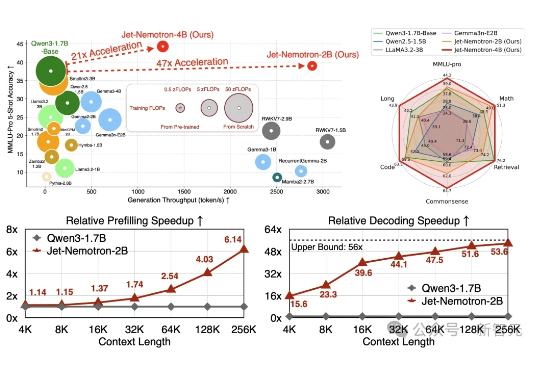
刚刚,英伟达新模型上线!4B推理狂飙53倍,全新注意力架构超越Mamba 2
刚刚,英伟达新模型上线!4B推理狂飙53倍,全新注意力架构超越Mamba 2Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
来自主题: AI技术研报
8907 点击 2025-08-26 19:34
 搜索
搜索
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
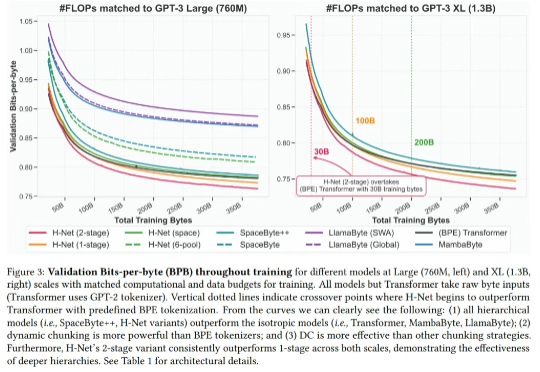
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。

2025 年 3 月 11 日,语音生成初创公司 Cartesia 宣布完成 6400 万美元 A 轮融资,距其 2700 万美元种子轮融资仅过去不到 3 个月。本轮融资由 Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital 和 Samsung Ventures 等跟投。
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。

Mamba 这种状态空间模型(SSM)被认为是 Transformer 架构的有力挑战者。近段时间,相关研究成果接连不断。而就在不久前,Mamba 作者 Albert Gu 与 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 一起共同创立的 Cartesia 获得 2700 万美元种子轮融资。
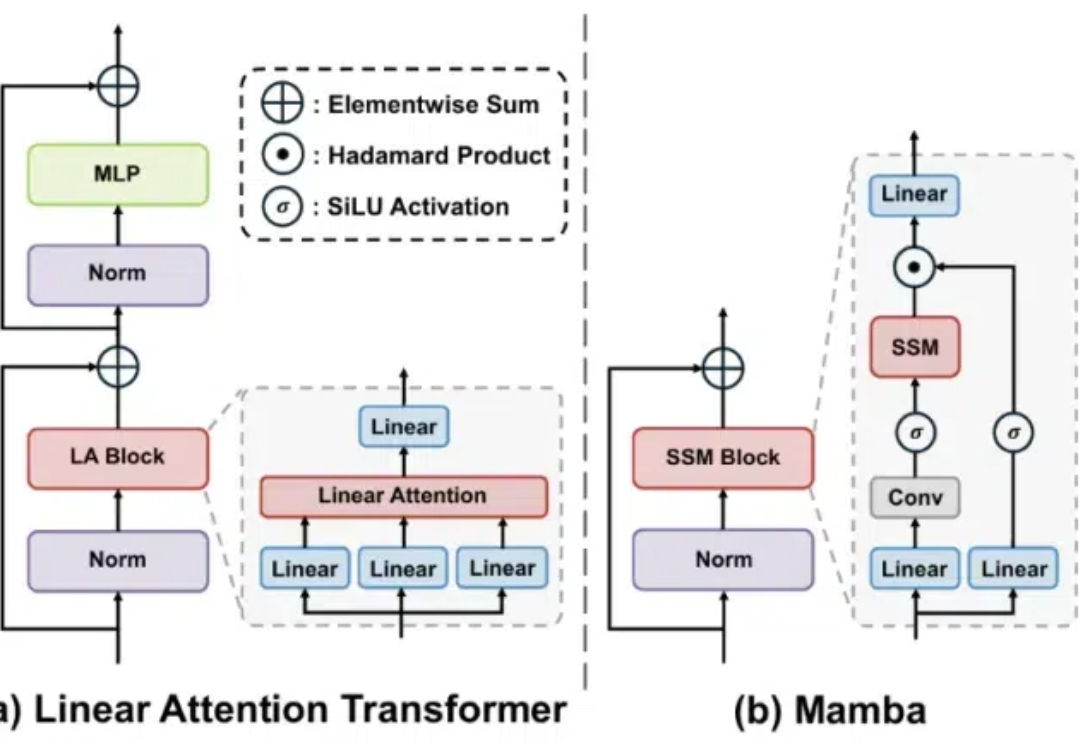
Mamba 是一种具有线性计算复杂度的状态空间模型,它能够以线性计算复杂度实现对输入序列的有效建模,在近几个月受到了广泛的关注。

Jamba是第一个基于 Mamba 架构的生产级模型。Mamba 是由卡内基梅隆大学和普林斯顿大学的研究人员提出的新架构,被视为 Transformer 架构的有力挑战者。
Mamba 虽好,但发展尚早。

Mamba 架构的大模型又一次向 Transformer 发起了挑战

TII开源全球第一个通用的大型Mamba架构模型Falcon Mamba 7B,性能与Transformer架构模型相媲美,在多个基准测试上的均分超过了Llama 3.1 8B和Mistral 7B。